Définitions et foire aux questions

Le GTSO Données propose des définitions et des réponses à des questions récurrentes sur les données de la recherche. Cette rubrique est amenée à évoluer. Une définition ou question est manquante ? Ecrivez-nous à l’adresse gtso_donnees@listes.couperin.org
Définitions
Archivage pérenne des données
L’archivage pérenne a pour fonction d’assurer la conservation à long terme des données, leur accessibilité tout en préservant leur intelligibilité, comme rendre accessible en lecture des données immuables (archives de documents administratifs, données de mesures expérimentales, résultats de simulations coûteuses à produire, etc.). Il a vocation à prévenir l’obsolescence des supports numériques.
En France, le CINES (Centre Informatique National de l’Enseignement Supérieur) propose un service d’archivage électronique pour les données scientifiques issues d’observations ou de calculs, les données patrimoniales (pédagogiques, publications, etc.) et les données administratives.
Les archivistes d’établissement peuvent guider les unités de recherche dans la définition des durées de conservation et le sort final de leurs données.
Pour aller plus loin :
« Stockage et archivage : fiche synthétique« , Doranum (2018)
Source :
Christine Hadrossek, Joanna Janik, Maurice Libes, Violaine Louvet, Marie-Claude Quidoz, Alain Rivet, Geneviève Romier, Guide de bonnes pratiques sur la gestion des données de recherche, janvier 2023.
Collecte des données
La collecte de données fait référence au processus de rassemblement, d’acquisition et d’enregistrement d’informations, qu’elles soient quantitatives ou qualitatives. Ce processus peut être effectué à partir de diverses sources telles que des enquêtes, des capteurs, des bases de données, des formulaires en ligne, des médias sociaux, etc. Il est essentiel de reconnaître la diversité des méthodes d’acquisition de données, lesquelles peuvent varier considérablement en fonction des différentes disciplines de recherche. La collecte des données peut entraîner leur réutilisation, c’est-à-dire leur utilisation à des fins dépassant et/ou prolongeant leur objectif initial.
Essentielle à chaque étape du cycle de vie des données, la collecte met en avant la nécessité d’une documentation transparente et du respect des normes scientifiques. Les jeux de données rigoureusement documentés dès le début garantissent la fiabilité pour les analyses futures. La qualité de cette documentation influence directement la validité des résultats, facilitant ainsi leur réutilisation ultérieure. Une bonne documentation ne fait pas seulement progresser la transparence et la reproductibilité de la recherche, elle favorise également la collaboration entre les chercheurs, renforçant ainsi l’efficacité du processus scientifique.
Cycle de vie des données
On parle de “cycle de vie des données” pour désigner les états successifs d’une donnée de recherche au cours d’un projet, qu’elle soit collectée ou produite. A chaque étape, des personnels d’appui sont à la disposition des chercheurs pour les accompagner.
Les ateliers de la donnée labellisés par Recherche Data Gouv ont pour mission d’aider les chercheurs à chaque étape du cycle.
Pour aller plus loin :
Faire entrer la science ouverte dans son projet ANR : un guide pratique (2023)
Data paper
Un data paper est un article scientifique dont la spécificité est de décrire les traitements opérés pour un ou des jeux de données publiés, notamment les méthodes de recueil, les opérations d’appariement et d’analyse de ceux-ci. Il détaille le potentiel de réutilisation des jeux de données publiés par ailleurs dans des entrepôts. Le PGD peut servir de trame. Si certaines revues « classiques » acceptent ces articles spécifiques, il existe également des revues spécialisées, appelées data journals. Comme pour les articles, les data papers bénéficient d’une relecture par les pairs (peer-reviewing), sont citables et reconnus dans les évaluations de l’HCERES.
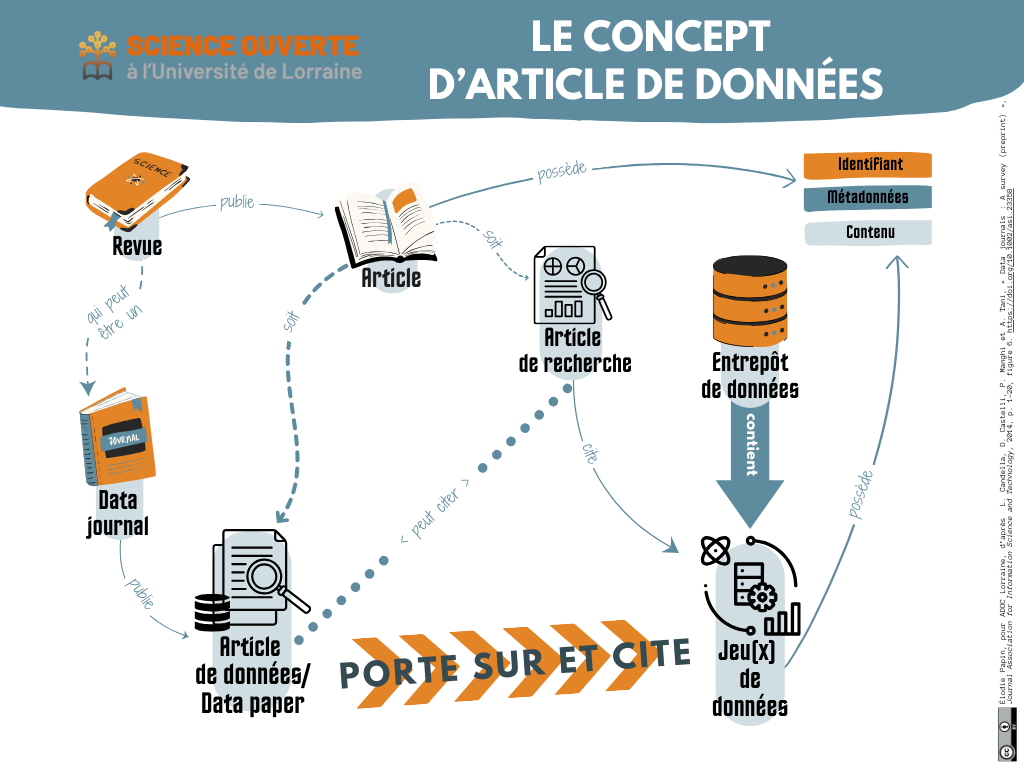
Le data paper est aussi connu sous le nom d’article de données, de data descriptor, data article, data briefs, resource announcements, research note ou encore data resource profile. Il n’existe pas encore de vocabulaire francophone commun pour ce type de ressource.
Un data paper permet de valoriser le travail de publication de données et d’attester de la qualité de ces dernières qui sont ainsi soumises à une évaluation par des pairs.
L’entrepôt Recherche Data Gouv offre un service de génération de data paper à partir d’un jeu de données déjà déposé sur celui-ci.
Pour aller plus loin :
Laurence Dedieu, « Publier un data paper, en 5 points« , CIRAD (2022)
Données de la recherche
Selon l’OCDE, les données de la recherche sont des « enregistrements factuels (chiffres, textes, images et sons) qui sont utilisés comme sources principales pour la recherche scientifique et sont généralement reconnus par la communauté scientifique comme nécessaires pour valider des résultats de recherche. » (OECD Principles and Guidelines for Access to Research Data from Public Funding, 2007).
Le périmètre des données de la recherche est circonscrit par ce texte à la notion d’éléments probants. Cela permet de déterminer ce qui devra ou non être conservé à long terme.
Les données de recherche concernent toutes les disciplines, du relevé d’un site archéologique à des enregistrements sonores, en passant par des données statistiques. Elles sont obligatoirement numériques (par exemple, les souches bactériennes ne sont pas des données). Leur nature peut donc varier en fonction des disciplines mais également des perspectives dans lesquelles les chercheurs se placent. A cet égard, la définition de l’OCDE, excluant du champ des données de recherche un certain nombre d’éléments, tels que les cahiers de laboratoire papier, peut apparaître restrictive.
Avant toute conservation, il convient de distinguer les types de données collectées dans le cadre d’une recherche : il peut s’agir de données produites ou de données issues du travail du chercheur ou de la chercheuse. De fait, l’ensemble des données produites sont issues d’un travail de contextualisation, les commentaires et analyses étant réalisés à partir de ces matériaux.
Complétant la définition de l’OCDE, l’Association des Archivistes Français, inclut les données de la recherche dans un ensemble plus vaste : les archives (y compris administratives) de la recherche.
Entrepôt de données
Un entrepôt de données est une base de données qui permet le dépôt de jeux de données de recherche. Une fois déposés, les jeux se voient attribuer un identifiant pérenne et une licence de réutilisation. Dédié à l’exposition et à la valorisation des données, il se distingue d’un data warehouse qui, lui, est orienté uniquement vers le stockage et la modélisation des données. Leur accès peut varier en fonction de leur nature, de la discipline et/ou des obligations du projet de recherche. Ainsi, certains jeux de données sont accessibles immédiatement, librement, d’autres selon un délai de mise à disposition (embargo), d’autres après en avoir fait la demande. Enfin, certaines données relevant de régimes juridiques particuliers (tels que le secret défense, la protection des données personnelles et/ou de santé ou encore le secret des affaires par exemple) ne peuvent être librement accessibles. De plus, il faut également noter que l’accès aux données dépend parfois des entrepôts choisis par leurs acteurs et non des données elles-mêmes.
Il existe de nombreux entrepôts de données, aux périmètres plus ou moins larges. Le chercheur souhaitant déposer et partager ses données doit se tourner en priorité vers un entrepôt disciplinaire. Si ce dernier n’existe pas, il peut alors se tourner vers l’entrepôt de sa tutelle ou Recherche Data Gouv, au sein duquel de plus en plus d’établissements disposent d’un espace institutionnel.

L’entrepôt est à la fois un lieu d’archivage sur le long terme et de consultation des données, en vue de leur réutilisation. Toutefois, l’entrepôt n’est ni le lieu de stockage temporaire à utiliser au cours du projet ni le lieu d’un archivage pérenne et définitif des données et des jeux de données. En effet, un archivage à très long terme est l’une des trois missions du CINES (Centre Informatique National de l’Enseignement Supérieur), établissement public national placé sous la tutelle du Ministère de l’ Enseignement Supérieur et de la Recherche (MESR). Le CINES est donc chargé de l’archivage pérenne de données électroniques.
Pour aller plus loin :
Recherche Data Gouv met à disposition un logigramme pour vous accompagner dans le choix de l’entrepôt
Identifiant pérenne
Un identifiant pérenne (ou persistent identifier pour PID) est une combinaison unique de lettres et/ou de chiffres attribuée à une ressource, qu’elle soit physique ou numérique : un article de revue, un jeu de données, un protocole de recherche, un livre, un auteur… Il permet d’identifier de manière univoque et immuable un objet ou une personne. Le DOI (pour Digital Objet Identifier) est un identifiant pérenne pour les objets numériques. Il est, par exemple, largement attribué aux articles de revues en ligne ou à des jeux de données déposés dans des entrepôts. Il fait aussi office de permalien, c’est-à-dire de lien maintenant dans la durée l’accès à la ressource numérique, même en cas de changement de localisation. L’attribution d’un DOI, par exemple à un jeu de données, est une étape essentielle pour respecter le F des principes FAIR, “Facile à trouver”. La plupart des entrepôts de données attribuent automatiquement un DOI. Il existe également des identifiants pérennes attribués à des personnes. C’est le cas notamment d’ORCID, d’IdHal ou encore d’IdRef. Ces identifiants uniques permettent de rattacher de manière univoque une production scientifique à son ou ses auteurs ainsi que de régler les problèmes d’homonymie. La science ouverte encourage ainsi les liens entre identifiants pérennes, par exemple entre DOI et ORCID, pour faciliter la découvrabilité des produits scientifiques.
Pour aller plus loin :
« La minute identifiants pérennes », Doranum (2022)
Jeu de données
Un jeu de données est un ensemble de données ayant une cohérence intellectuelle, intentionnelle ou formelle. Collectées ou produites, les données qui le composent peuvent être de nature différente (textes, tableur, images fixes ou animées, sons, etc.)
Par exemple, une photographie d’un champ, une analyse de sa terre et un relevé hygrométrique de ce champ peuvent constituer un jeu de données cohérent intellectuellement, même s’il est composé d’objets hétérogènes. De même, un ensemble de tests de matériaux peut aussi constituer un jeu de données, car la forme des données est homogène, même si elle porte sur des matériaux très différents les uns des autres. Ou encore : un chercheur ou une chercheuse peut constituer des données structurées à partir d’archives notariales afin d’illustrer une étude en histoire sur les pratiques et habitudes concernant l’héritage d’une population.
Licences d’utilisation
Une licence permet à l’auteur d’une production (qu’il s’agisse d’un article, d’un chapitre d’ouvrage, d’un logiciel ou encore d’un jeu de données) d’en fixer les règles d’utilisation par un tiers. Par exemple, d’autoriser ou non la modification de la production ou son usage commercial. Toute licence exige au minimum de citer le ou les auteurs.
La licence ouverte est conçue par Etalab pour faciliter et encourager la réutilisation des données publiques mises à disposition gratuitement. Cette licence de diffusion ouverte concerne l’ensemble des données publiques au sens du CRPA, c’est-à-dire toutes les données de la recherche sauf celles issues d’une recherche financée majoritairement par des acteurs privés. Cette licence permet la reproduction, la modification et l’utilisation commerciale si la mention d’attribution et la date de dernière mise à jour sont précisées.
La plus connue, la licence Creative commons (CC), créée par Lawrence Lessig, Hal Abelson et Eric Eldred, permet d’accorder des droits de réutilisation et de reproduction à la personne qui consulte votre ressource. Elle enrichit le droit d’auteur qui s’applique par défaut. Elle fonctionne comme des briques que vous décidez d’apposer ou non à votre ressource.
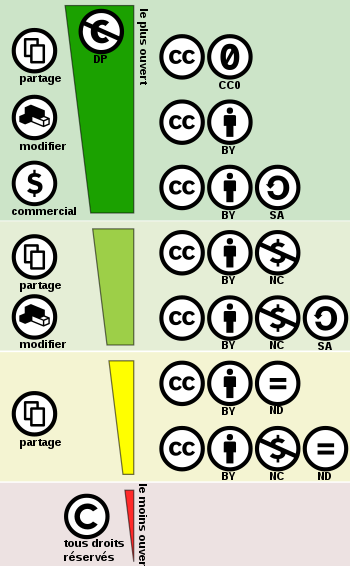
- 0 : l’auteur renonce au maximum de ses droits d’auteur. Sauf limites imposées par la loi, la réutilisation, la modification et l’amélioration du contenu est autorisé ;
- BY : mention d’attribution, obligation de créditer l’auteur ;
- NC : usage non commercial, ce qui restreint les possibilités de réutilisation ;
- ND (non derivative) : pas de modification, ce qui rend impossible l’intégration à tout ou partie d’une oeuvre composite ;
- SA (share alike) : partage autorisé mais dans les mêmes conditions/la même licence que celle choisie par l’auteur original, ce qui réduit l’interopérabilité des données.
Les Licences OKF Open Knowledge Fundation sont plutôt orientées bases de données :
- Licence ODC-by : Open Database Commons : équivalent CC-by
- Licence ODC-ODBL Open database License : équivalent CC-SA
- Licence PDDL Public domain dedication and license : équivalent CC-0
Elle n’affecte pas les brevets, le droit à l’image ou le droit à la vie privée.
La Licence GNU General Public License concerne les logiciels (libres) et les programmes.
Pour aller plus loin :
GT Juridique du GTSO Couperin, « Licences libres pour la Science Ouverte », 2024.
Métadonnées
Les métadonnées sont, au sens premier, des « données sur les données ». Selon la BnF (Bibliothèque Nationale de France), une métadonnée est un ensemble structuré d’informations (auteur, date et lieu de publication, édition, etc.) décrivant une ressource quelconque. Si l’on imagine un jeu de données sous la forme d’une boîte de conserve, alors les métadonnées équivalent à l’étiquette qui orne celle-ci et en décrit le contenu (date de fabrication, créateur etc.). L’objectif des métadonnées est, en particulier, de contextualiser les données afin de rendre possible et de faciliter leur consultation, leur compréhension et leur échange et ainsi de permettre de pérenniser leur utilisation.
Il existe plusieurs types de métadonnées :
- Les métadonnées embarquées : elles sont intrinsèquement liées aux fichiers de recherche. Par exemple, lorsqu’une photographie est prise, elle contient des métadonnées créées immédiatement : date, lieu, appareil utilisé, configuration, etc.
- Les métadonnées enrichies (externes) : elles sont complétées manuellement, soit dans un fichier à part, soit directement au moment du dépôt dans un entrepôt de données. Par exemple pour un jeu de données : les mots-clés, le sujet, le laboratoire ou organisme, le nom du projet, la licence, etc.
Il existe des standards de métadonnées, c’est à dire des listes normées d’éléments descriptifs, génériques (DublinCore, DataCite…) ou propres à certaines communautés (DDI en SHS, EML pour la biodiversité…). Certains entrepôts imposent leur propre schéma de métadonnées. C’est le cas, par exemple, de Recherche Data Gouv, qui propose un schéma reprenant en partie d’autres standards (DataCite ; DDI…).
Partage des données
Le partage des données de recherche désigne la mise à disposition des données au-delà de l’équipe projet. Il concerne les données froides qui doivent être conservées sur le moyen ou long terme. Ce partage peut s’effectuer par exemple via la publication des données dans un entrepôt de données ou encore l’indexation dans un catalogue.
Attention, le partage n’est pas automatiquement synonyme d’ouverture et de réutilisation libre des données. En effet, il est possible de partager des données en accès restreint, à la demande, par exemple en requérant l’adresse mail et les motivations du demandeur avant consultation. Le partage en accès restreint peut être justifié dans certains cas, par exemple en cas de partenariat industriel, si la convention le prévoit.
La question du partage et / ou de l’ouverture des données en fin de projet est abordée dans la cinquième partie du modèle ANR de plan de gestion de données.
Plan de gestion de données
Un plan de gestion de données | PGD (ou Data Management Plan | DMP) est un livrable (document formel) qui détaille la façon dont vous obtenez, documentez, analysez et utilisez vos données au cours de votre recherche et une fois le projet terminé. Document évolutif, rédigé tout au long du projet, il décrit les méthodes et les processus de création, de fourniture, de maintenance, de conservation et de protection des données.
Il sert à :
- fiabiliser les données et faciliter leur gestion
- anticiper et favoriser leur éventuelle diffusion
- décrire la façon dont les données scientifiques d’un projet de recherche seront produites, traitées, diffusées, protégées…
Surtout :
- Le PGD spécifie quelles données sont collectées ou générées, comment celles-ci sont gérées, partagées et préservées pendant et après le projet.
- Il est un outil de gestion de projet et de management des risques qui concerne tous les partenaires du projet.
- Il est exigé par les organismes de financement et les institutions.
- Il s’agit du seul livrable concret pour la gestion des DR.
Les agences de financement exigent qu’un PGD soit rédigé à intervalle régulier. Par exemple, l’ANR demande une première version à 6 mois puis une version finale à la fin du projet.
Pour aller plus loin :
Plan de gestion de données : fiche synthétique, DoraNum (2023)
Principes FAIR
Les principes FAIR sont issus du collectif Force 11 comprenant des chercheurs, enseignants, bibliothécaires, ingénieurs, archivistes, éditeurs, bailleurs de fonds de la recherche, une représentation équitable des acteurs de la donnée. Leur but : promouvoir une gestion saine des données comme part essentielle des bonnes pratiques de la recherche.

- Des données « Faciles à trouver »
Pour être trouvables, les données doivent :
a. être documentées et référencées sur les moteurs de recherche ;
b. avoir des identifiants uniques et pérennes ;
c. comprendre des fichiers et dossiers clairement nommés, organisées et documentés. - Des données « Accessibles »
a. Dans un entrepôt de diffusion certifié ;
b. stockées sur deux supports fiables dont un à distance pendant le projet ;
c. archivées en partie à l’issue du projet. - Des données « Interopérables »
a. Schémas de métadonnées partagés et adaptés à la discipline ;
b. Formats connus, ouverts, documentés, partagés, vocabulaire FAIR. - Des données « Réutilisables »
a. Conformité avec le RGPD, la Loi Lemaire et le droit de la propriété intellectuelle ;
b. Licences de diffusion autorisant la réutilisation, clairement apposée, mention de provenance explicite et traçable, ancrage dans des standards de la communauté scientifique ;
c. Data paper explicitant les implications du jeu de données rédigé.
Pour aller plus loin :
« Les principes FAIR », Doranum (2019)
Reproductibilité de la recherche
La reproductibilité est un sujet complexe qui s’inscrit à la fois dans l’histoire longue des sciences et dans l’actualité scientifique depuis une vingtaine d’années. En effet, plusieurs études ont alerté les communautés scientifiques sur le nombre croissant de travaux qui s’avéraient “non reproductibles”, tant et si bien que les spécialistes parlent aujourd’hui de “crise de la reproductibilité” (Monya Baker, 2016). Cependant, cette prise de conscience, favorisée notamment par le développement de la science ouverte, se traduit par un foisonnement de travaux épistémologiques et techniques sur le sujet.
Au regard de ce contexte et de cette complexité, comment définir ce que pourrait être une recherche reproductible ? L’Association for Computing Machinery (ACM) distingue trois concepts : la “répétabilité” ; la “reproductibilité” et la “réplicabilité”. Alors que la “répétabilité” désigne une expérience “rejouée” par les mêmes acteurs à l’aide du même dispositif, la “reproductibilité” permet à d’autres acteurs de mener l’expérience sans changer de dispositif expérimental. La “réplicabilité” désigne, elle, le fait que les acteurs et le dispositif utilisés initialement changent, mais que les résultats se vérifient malgré tout. Cependant, comme le montre l’illustration ci-dessous, ces questions sont ouvertes et peuvent convoquer d’autres concepts comme la “généralisation” et la “robustesse”.
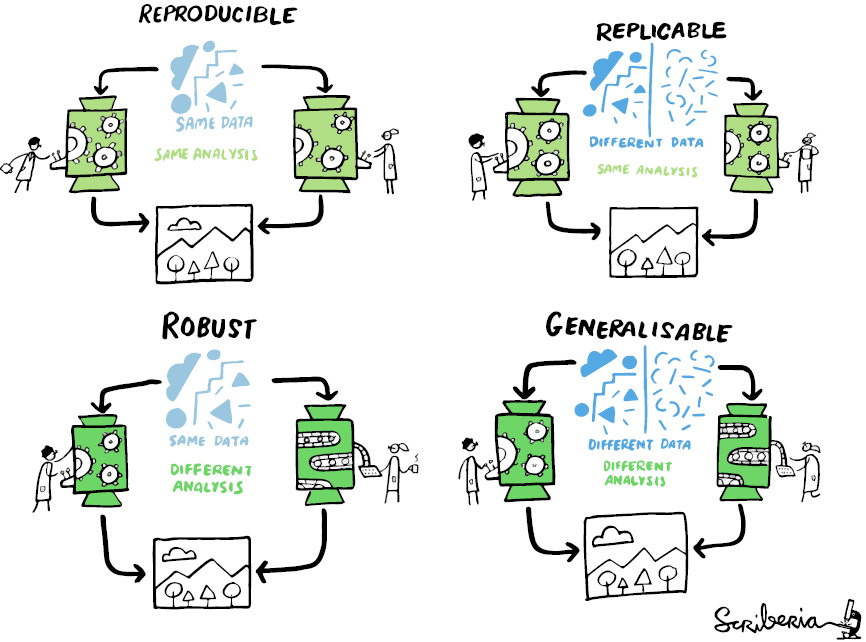
Si le respect des principes FAIR est une nécessité, ils sont loin d’être suffisants car ils n’insistent que sur les conditions de la réutilisation et la documentation des données. En effet, la question de la reproductibilité est bien plus large et engage l’ensemble du processus de recherche, des méthodes de travail aux données produites, en passant par les outils utilisés. Cela implique notamment de faire attention aux logiciels et standards utilisés lors de la production et du traitement des données, de rédiger des métadonnées qui soient les plus précises possibles ou encore de déposer ses données dans un entrepôt ouvert. Enfin, cela nécessite une documentation importante concernant l’ensemble du processus de production des données, auquel le Plan de Gestion de Données concourt, sans être suffisant.
Cependant, il est nécessaire de préciser que toutes les recherches ne sont pas, par leur nature, reproductibles et que cela ne préjuge en aucun cas de leur scientificité. Ainsi, ce qui compte pour faire avancer le partage des connaissances, c’est que les recherches soient transparentes et traçables.
Pour aller plus loin :
- Artifact Review and Badging Version 1.1”, Association for Computing Machinery, 24 août 2020.
- “Les données, le nerf de la reproductibilité de la recherche”, Webinaire du GTSO Couperin, 4 décembre 2023.
- Monya Baker, “1,500 scientists lift the lid on reproducibility”, Nature, 25 mai 2016.
- Sophie Duchesne et Camille Noûs, “Apories de la mise en banque : retour d’expérience sur la réutilisation d’enquêtes qualitatives”, Tracés, n°19, 2019.
- Andréa Chiarelli, Lucia Loffreda, Rob Johnson, Jean-François Nominé, Manon Parrinello, Marc Rubio, Publication et données reproductibles de la recherche. Que faire ?, Knowledge Exchange, 2023.
- Sylvérie Herbert, Hautahi Kingi, Flavio Stanchi, Lars Vilhuber, “La reproductibilité de la recherche en économie : un cas d’étude”, Banque de France, 2021.
Science ouverte
La science ouverte (« Open science ») est un mouvement visant à rendre accessibles les processus et résultats de la recherche à toutes sortes de publics, appartenant ou non au milieu de la recherche. Elle invite à repenser les manières de faire de la recherche afin d’augmenter la transparence et la visibilité du travail des chercheurs.
Le mouvement de la science ouverte s’est d’abord développé à partir de celui de l’Accès Libre (« Open Access »), qui désigne la contestation, de la part de communautés scientifiques, de l’hégémonie de grands éditeurs scientifiques sur la publication et diffusion de la majorité des résultats de la recherche.
Source : Marie Latour, Annaïg Mahé, Olivier Copin, Bénédicte Sauvage, On fait le point sur les données de la recherche avec Sorella !, 2023.
Cette volonté de démocratiser la science a depuis dépassé la seule question des publications. Elle vise aujourd’hui à faciliter le partage – autant qu’il est possible et pertinent – de matériaux et produits de recherche variés (données, logiciels, méthodes…), d’encourager leur réutilisation pour des recherches ultérieures et s’appuie sur des recommandations internationales et des politiques publiques de niveau national et européen. Aujourd’hui, la science ouverte concerne l’ensemble des processus scientifiques, des données aux publications, des politiques publiques aux évaluations par les pairs.
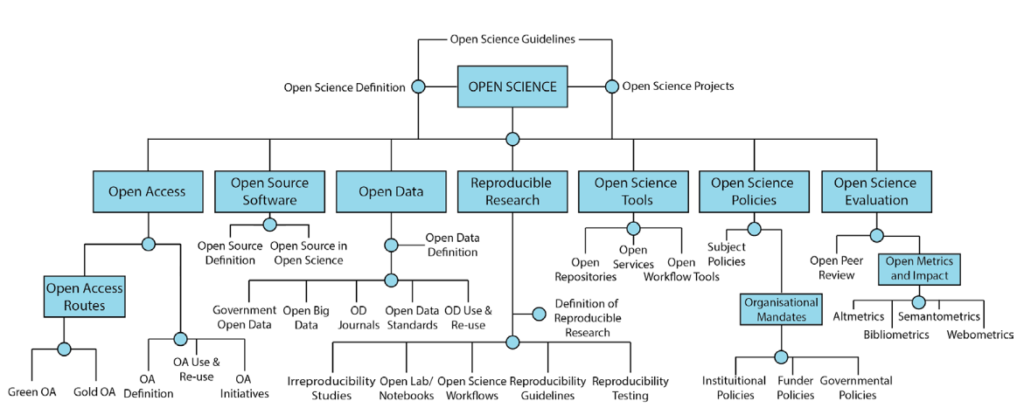
Source : Tennant, Jonathan, Jennifer E. Beamer, Jeroen Bosman, Björn Brembs, Neo Christopher Chung, Gail Clement, Tom Crick, et al. 2019. « Foundations for Open Scholarship Strategy Development« , MetaArXiv, 2019.
Stockage des données
Le stockage désigne l’enregistrement des fichiers de données de recherche sur des solutions d’hébergement temporaires, tels qu’un cloud, un serveur ou un disque dur, le temps du projet de recherche.
Il ne constitue en aucun cas une solution pérenne de conservation. Le stockage est une étape intermédiaire durant laquelle la règle de sauvegarde dite “3-2-1” est essentielle. Il est effectué sur des outils (voir un tableau comparatif) dont l’accès est limité et contrôlé, individuels (un disque dur d’un ordinateur personnel, par exemple) ou bien collaboratifs (un cloud partagé).
La section des modèles de plan de gestion de données portant sur le stockage concerne donc uniquement les outils permettant l’hébergement des données chaudes, sur lesquelles des actions sont menées, et se différencie de l’archivage, qui intervient en fin de projet.
FAQ
Quel est le meilleur moment pour gérer mes données ?
Dès que possible ! Il vaut mieux organiser en amont les fichiers produits dans le cadre du projet afin d’en assurer une gestion plus fluide au quotidien. Ce travail, réalisé en même temps que la recherche, facilitera la rédaction d’un PGD (voir la définition ci-dessus).
Dans la perspective d’un dépôt des données, l’anticipation est indispensable : il est plus difficile de publier un jeu de données correctement structuré si on ne l’a pas pensé dès sa création. Par ailleurs, cette préparation permet d’envisager les éventuels coûts de stockage, mais aussi de ressources humaines nécessaires à la gestion des données.
Comme les données, les métadonnées doivent être structurées de manière à renseigner au mieux les informations qui permettront de réutiliser les données qu’elles décrivent.
Pour trouver les données décrites, il convient de les déposer sur l’entrepôt le plus adéquat (voir la définition ci-dessus).
Pour aller plus loin :
Sciences Po : équipes données, « Gestion des données de recherche. Kit de survie de 7 à 77 ans »
Les logiciels et codes sources sont-ils des données ?
Les logiciels et codes sources peuvent s’apparenter à un type particulier de données de la recherche suivant le choix de définition de ces dernières mais ils ont leurs caractéristiques propres :
- les logiciels sont intrinsèquement vivants alors que les données sont plutôt statiques,
- ils sont exécutables contrairement aux données,
- les logiciels s’appuient sur des dépendances et tout un environnement logiciel et matériel qui évolue, ce qui complexifie les questions de reproductibilité par rapport aux données,
- les codes sont le résultat d’une création – il s’agit d’ »œuvres de l’esprit » alors que les données sont des résultats d’une observation ou de faits,
- par conséquent ils correspondent à un cadre juridique différent de celui des données,
- enfin la durée de vie des logiciels est généralement plus courte que celle des données de la recherche.
Les logiciels sont considérés comme des productions scientifiques à part entière aux côtés des données de la recherche et des publications avec lesquelles ils constituent les trois piliers de la préservation des connaissances scientifiques.
Il est vivement conseillé de rédiger des plans de gestion dédiés spécifiquement aux logiciels (Software Management Plan) afin d’initier une réflexion autour de leur développement, leur maintenance et de garantir leur accessibilité et leur réutilisabilité à court et long terme. Il est également possible d’identifier l’existence d’un code source développé et utilisé au sein d’un projet de recherche via l’ajout et la description d’un type spécifique de production scientifique dans le plan de gestion de données. DMP Opidor permet de séparer et décrire précisément plusieurs produits de recherche. C’est particulièrement important dans le cas de logiciels qui sont nécessaires pour accéder et interpréter les données de recherche. Ils devraient être, dans la mesure du possible, rendus librement accessibles parallèlement aux données.
Pour cela il est possible de profiter de l’interopérabilité entre les plateformes Software Heritage et HAL pour mettre en place les bonnes pratiques en matière de science ouverte : l’archivage, le référencement, la description et la citation (avec mention de l’auteur) du code source de logiciels.
Pour aller plus loin :
- Le Comité pour la Science ouverte (COSO) dispose d’un collège qui se consacre aux « Codes sources et logiciels ». Ce dernier produit régulièrement des rapports disponibles sur le site du COSO.
- « Déposer le code source d’un logiciel » sur HAL.
Sources :
- Teresa Gomez-Diaz, Tomas Recio, « Research Sofware vs. Research Data I : Towards a research data definition in the open science context, F1000 Research (2022)
- Daniel S. Katz, Kyle E. Niemeyer, Arfon M. Smith et al., « Sofware vs. data in the context of citation », PeerJ Preprints (2016)
- Daniel S. Katz, Morane Gruenpeter, Tom Honeyman, et al.,« A fresh look at FAIR for Research Software », arXiv (2021)
Quels types de données est-ce que je produis ?
Lors de la rédaction d’un plan de gestion de données, cette question se pose. Elle donne l’occasion de réfléchir à la nature des données produites au cours d’un projet de recherche et aux modalités de conservation et de partage que cela implique. En effet, certaines données sont plus précieuses que d’autres ; c’est notamment le cas des données d’observation, uniques et irremplaçables par nature.
On distingue généralement 5 grandes catégories de données :
- D’observation : ce sont les données générées par une observation en temps réel. Par exemple, des réponses à un entretien, le comptage d’animaux dans leur environnement, des relevés de température… Elles ne peuvent être reproduites et doivent donc faire l’objet d’un soin tout particulier, en leur attribuant notamment des métadonnées très précises pour disposer de leur contexte de génération.
- De simulation : ce sont les données issues de modèles informatiques, par exemple de prévision climatique ou économique, ou encore une simulation d’expérience. Le modèle est ici plus important que les données elles-mêmes, qui sont en principe reproductibles si le modèle est bien décrit.
- D’expérimentation : ce sont les données produites dans le cadre de tout type d’expérience, en laboratoire comme sur le terrain, souvent obtenues à partir de matériel spécifique. Si les conditions de l’expérience sont bien décrites et conservées, par exemple au travers d’un cahier de laboratoire, elles doivent être reproductibles. Mais parfois le coût et le temps nécessaires à la reproduction sont très importants ; en astrophysique par exemple. Là encore, les métadonnées doivent être très précises pour pouvoir disposer de toutes les informations nécessaires à la compréhension de ces données. Le lien entre cahier de laboratoire électronique et jeux de données en est d’autant plus important.
- Dérivées ou compilées : ce sont des données transformées à partir de données brutes. Par exemple, cela peut-être une base de données composée de photographies réalisées au cours d’une recherche ; ou encore une compilation de données obtenues suite à un travail de text and data mining. Bien qu’elles puissent être reconstituées en repartant des données brutes, le processus reste très chronophage.
- De référence ou canoniques : ce sont les données communément reconnues par la communauté scientifique comme immuables, comme le tableau périodique des éléments, les cadastres, les théorèmes mathématiques… Mais également les données qui font référence et sur lesquelles les chercheurs peuvent s’appuyer : collections statistiques, données Insee, données en génomique, jurisprudence, archives…
J’ai l’impression de ne pas avoir de données. Est-ce vraiment le cas ?
Les données peuvent revêtir une multitude de formes : quantitatives, qualitatives, relevés de terrain sous forme de fichiers tabulés, entretiens enregistrés, audio, vidéo, etc. Il arrive que, pour certains projets, le terme de « données » paraisse inadapté. La définition est large (voir la définition des données de la recherche ci-dessus).
En philosophie, par exemple, on peut avoir l’impression de ne pas en produire. Pour autant, il existe dans cette discipline de nombreux matériaux produits préalablement à la publication d’un article. Par exemple, une base de données compilées de textes de philosophes antiques lemmatisés. Si le fait de rédiger un plan de gestion de données ne vous semble pas nécessaire, alors il faut remettre en perspective les matériaux produits avant d’écrire un article. Sur quoi vous appuyez-vous pour le réaliser ? Vous pouvez penser à tous les matériaux auxquels vous tenez vraiment et qui seraient irremplaçables ou très longs à recréer, s’ils n’étaient pas sauvegardés ou conservés en sécurité. Ainsi, les sources réutilisées peuvent être considérées comme des données, mais aussi les notes, les brouillons, les logiciels, les flux de travail, les protocoles. Tous ces ensembles peuvent former ensemble un jeu ou des jeux de données cohérents, à partir desquels un PGD pourrait être rédigé (voir la définition ci-dessus).
Une fois publiées, les données peuvent être réutilisées, totalement ou partiellement. La sélection de données que vous allez faire pour un projet et sur lesquelles il y aura peut-être des droits de réutilisation ou des contraintes de sécurité, aura contribué au résultat scientifique. Lorsque vous utilisez des données préexistantes (qu’elles fassent partie de bases « ouvertes » ou « fermées »), pensez à vous renseigner et à communiquer sur les licences qui encadrent ces données, notamment en matière de droit de réutilisation et diffusion (voir la définition des licences ci-dessus).
L’entrepôt de données assure la préservation et l’accessibilité des données en vue de leur consultation et de leur réutilisation (voir la définition ci-dessus). Par ailleurs, notons l’existence des codes sources et logiciels, outils qui sont utiles au traitement des données déposées, souvent conçus au cours du projet de recherche. Ils peuvent aussi être considérés comme des données de recherche du moment qu’ils servent, par exemple, à traiter les données. Toutefois, en ce qui concerne les codes sources et logiciels à part entière, il est conseillé de privilégier un dépôt conjoint dans Software Heritage et HAL. Il s’agit d’une archive ouverte spécialisée pour ces contenus lancée en 2016 par l’Inria (Institut national de recherche en informatique et en automatique) et soutenue par l’UNESCO. Le dépôt d’un code source peut aussi être cité directement dans HAL.
Toutes ces données ne seront pas nécessairement publiées ni accessibles à toutes et à tous, mais elles constituent la matière première de votre recherche, qui peut être décrite dans votre plan de gestion des données.
Dois-je conserver l’ensemble des données produites ?
Au cours de leurs recherches, les chercheurs produisent ou collectent de nombreuses données. Cependant, ils opéreront ensuite un travail de sélection et des distinctions apparaîtront entre les données produites ; les données traitées ; les données retenues et, au final, les données publiées ; le volume de données diminuant à chaque étape.

Les chercheurs doivent alors trouver un équilibre entre la conservation et la suppression des données. S’il n’est pas nécessaire de conserver l’ensemble des données produites, la seule conservation des données publiées peut parfois s’avérer insuffisante. Le chercheur pourrait alors conserver les données qui permettent la compréhension et l’évaluation du projet mais également sa reproductibilité, voire son approfondissement.

Au-delà de ces raisons scientifiques, il faut garder à l’esprit qu’il sera impossible d’un point de vue technique, de sauvegarder, l’ensemble des données de recherche produites par l’ensemble des scientifiques de la planète. Enfin, le stockage des données et l’ouverture de data centers toujours plus grands pour les accueillir ont des impacts écologiques non négligeables qu’il faut également prendre en compte dans les réflexions.
Ainsi, au regard de ces différents éléments, le chercheur doit opérer une sélection entre les données qu’il doit conserver et les données qu’il peut supprimer. Il peut être accompagné dans ce choix par l’archiviste de sa tutelle.
Puis-je refuser de partager mes données ?
Depuis 2016, si la production des données est effectuée dans le cadre d’une recherche financée majoritairement par des fonds publics (les salaires des enseignants-chercheurs étant comptabilisés dans le calcul), alors ces données doivent être partagées et librement consultables. Cependant, il est nécessaire de tenir compte des spécificités juridiques du corpus, de la nature des données… pour déterminer les modalités de leur diffusion. L’ouverture des données repose sur un principe central : elles doivent être « aussi ouvertes que possible, aussi fermées que nécessaire ».
Ces principes sont régis, en France, par plusieurs textes : le Code de la Recherche (art. L533-4) et le CRPA (art. L311-1 et L.311-2). Le CRPA introduit la notion de « document achevé » pour déterminer le moment où un document est communicable. Le Comité pour la Science Ouverte recommande de considérer une donnée comme achevée quand elle est « sous-jacente à une publication ».
En conséquence, un chercheur ne peut refuser de partager ses données achevées, sauf dans le cadre d’un certain nombre d’exceptions légales telles que la protection des données personnelles et de santé ; le secret défense ; la sûreté de l’État ou encore le secret des affaires, entre autres.
Pour aller plus loin :
Cécile Arènes, Lionel Maurel, Stéphanie Rennes, Guide d’application de la Loi pour une République numérique pour les données de la recherche, Comité pour la science ouverte (2022)
Je ne pense pas que les données de mon projet seront réutilisées. Est-il utile de les partager ?
N’oubliez pas que la première personne susceptible de réutiliser les données, c’est vous ! Chaque donnée ayant servi à un travail de recherche est unique et pourra être citée et réutilisée.
Cependant, tout ne doit pas forcément être sauvegardé. Un tri préalable et une éventuelle destruction doivent être réalisés car toutes les données produites au cours d’un projet n’ont pas vertu à être conservées de façon pérenne.
La préservation des données est nécessaire dans de nombreuses disciplines. Leur diffusion peut permettre de faire émerger des pistes de recherche. Par ailleurs, une réutilisation partielle ou totale d’un jeu de données peut éclairer des recherches appartenant à d’autres disciplines.
Ma thèse n’est pas financée, dois-je partager obligatoirement mes données ?
A l’heure actuelle, il n’existe pas d’obligations clairement édictées dans la loi, imposant aux doctorants non financés de partager leurs données. Cependant, de par leurs activités de recherche ainsi que leur appartenance à un établissement d’enseignement supérieur (public ou privé) et à un laboratoire, ceux-ci concourent à la recherche publique. Or, comme l’indique le Code de la Recherche, cette dernière a pour objectif “Le partage et la diffusion des connaissances scientifiques en donnant priorité aux formats libres d’accès” et “L’organisation de l’accès libre aux données scientifiques” (article 112-1). En conséquence, les doctorants non financés sont aussi concernés par l’ouverture et le partage de leurs données. De plus, certaines universités (comme Paris-Saclay par exemple) incluent dans leur “Charte du doctorat” une clause concernant la science ouverte, engageant l’ensemble de leurs doctorants à déposer leurs productions dans une archive ouverte et à produire des données FAIR.